TEF : comment détecter les cas de fraudes dans les questionnaires à choix multiple ?
mardi 25 septembre 2018
Nous vous proposons de partager notre expertise sur l’évaluation avec cette série de publications scientifiques. Découvrez ci-dessous un article sur les différentes méthodes de détection des fraudes dans les questionnaires à choix multiples.
L’importance de la prévention et de la détection des cas de fraudes.
Lorsque la passation d’un test présente un enjeu fort pour les candidats, il peut être tentant pour ces derniers de recourir à des stratagèmes leur permettant d’améliorer artificiellement leurs résultats. Cela peut consister en de la préparation intensive au moyen d’annales, qui constitue néanmoins un apprentissage, à la recherche matériel officiel de test diffusé illicitement (par exemple des items mémorisés par des candidats précédents rémunérés à cette fin) ou à la copie sur un voisin de test plus compétent.
Si un candidat présente ce type de comportements lors d’un test, cela remet en cause l’intégrité des résultats délivrés et le principe d’équité entre les candidats. Il est donc important de mettre en place des dispositifs de sécurité pour prévenir et/ou détecter d’éventuels cas litigieux. Pour cela, le rôle de surveillance des centres d’examens est essentiel, mais il doit être complété par une analyse statistique des réponses des candidats pour détecter d’éventuelles situations problématiques.
Il existe de multiples méthodes destinées à détecter des patrons de réponses aberrants de candidats, qui ne renvoient pas nécessairement à des tentatives de triche. Il convient donc d’identifier les méthodes les plus adaptées par rapport à l’objectif visé (détecter des tentatives de triche visant à améliorer le résultat) pour renforcer l’efficacité du dispositif de surveillance.
Partir du modèle de Rasch, pour repérer les comportements aberrants.
Le modèle de mesure mis en œuvre dans le cadre des épreuves à choix multiple du Test d’évaluation de français est le modèle de Rasch. Il s’agit d’un modèle paramétrique permettant d’exprimer sur une échelle la difficulté relative des items et la compétence relative des candidats. Ce modèle permet notamment d’indiquer la probabilité de réussite à un item de difficulté donné d’un individu ayant un niveau de performance donné (score Rasch), que l’on peut comparer à sa réussite ou non à l’item.
Plusieurs tests statistiques, appelés indices, ont été développés sur la base de cette propriété pour détecter les comportements aberrants. Ces indices quantifient la normalité d’une série de réponses d’un candidat. Le patron des réponses d’un candidat dont l’indice est trop éloigné de l’indice de référence, sera considéré comme improbable. C’est notamment le cas si le candidat répond correctement à diverses questions difficiles alors qu’il échoue par ailleurs à des questions plus faciles.
Pour déterminer les tests statistiques les plus efficaces, nous étudions leur risque d’erreur et puissance statistiques dans des situations simulées représentatives des types de fraudes que nous souhaitons pouvoir mettre en évidence.
Simulations et analyses des résultats pour identifier les méthodes les plus efficaces.
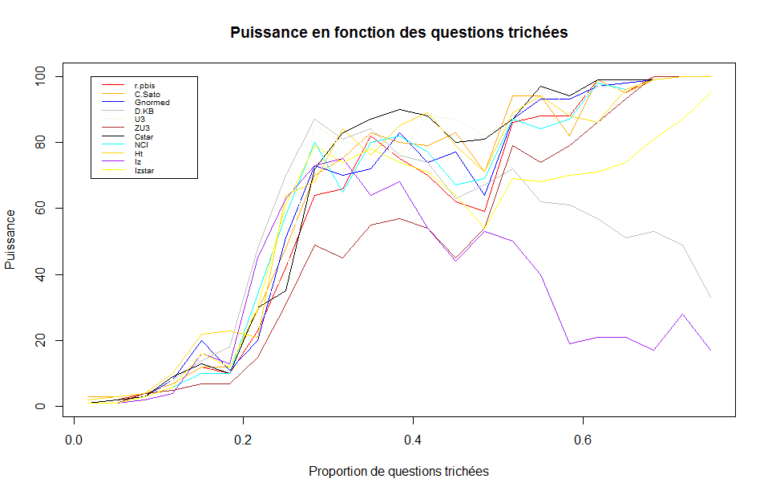
Dans une première analyse, nous avons simulé une situation avec 100 candidats fraudeurs parmi 2500 qui ont pris part à un examen fictif comportant 60 questions, en les faisant tous tricher sur les mêmes questions (simulant ainsi une situation de divulgation illicite d’un ensemble d’items auprès de candidats). Nous avons fait varier le nombre de questions faisant l’objet de triche entre 1 et 45, en limitant les risques de triche aux 45 questions les plus difficiles parmi les 60. Les résultats montrent que pour une proportion de fraude de 40% (24 questions sur 60), certaines méthodes comme Cstar sont assez puissantes(voir la figure) : elles détectent bien la fraude dans 90% des cas environ.
La pente des courbes de puissance est la plus élevée entre les proportions 20 et 40% de questions fraudées (9 à 18 questions) pour quasiment toutes les méthodes. Cela indique que les statistiques sont assez sensibles au nombre de questions dévoilées et à leur difficulté. Les puissances de ces statistiques sont toutefois variables selon la méthode. Dans cette configuration, la méthode « Cstar » (courbe noire) est celle qui, en moyenne, est la plus performante en termes de détection des cas aberrants. La statistique « lz » étant puissante jusqu’aux environs de 30% des questions dévoilées avant de chuter au-delà de cette proportion.
Puissances (en %) de différents modèles en fonction de la proportion de questions « trichées » (ici, seules les 75% des questions les plus difficiles sont susceptibles d’être fraudées)
Dans d’autres configurations, comme par exemple le cas où seules les 15 questions les plus difficiles sont sujettes à fraude, les indices de tests sont logiquement plus performants. Lorsque les candidats fraudent uniquement sur les questions les plus difficiles, ils sont plus facilement détectés. Ainsi, en fraudant sur 15% des questions (9 questions sur 60) qui font parties des 25% les plus difficiles, le taux de détections est d’environ 50% pour certains indices comme Ht ou lzstar, et atteint 90% lorsque la triche concerne les 25% (15 sur 60) des questions les plus difficiles.
Les performances des différentes méthodes dépendent de la nature de la fraude et de son étendue. Une connaissance a priori des items les plus susceptibles d’être sujets à la fraude permettrait d’optimiser le choix des méthodes à mettre en œuvre pour mieux s’adapter à la situation. Des questions sont-elles effectivement apprises par cœur et partagées ? Les réponses des questions les plus difficiles sont-elles vraiment les plus susceptibles d’être apprises avant le test ?