![]()
![]()

Publié le 29 octobre 2018
Nous vous proposons de partager notre expertise sur l’évaluation avec cette série de publications scientifiques. Découvrez ci-dessous un article sur les différentes méthodes de détection des fraudes par copie sur un autre candidat.
Dans un récent article, nous avons décrit nos travaux sur la détection des cas de fraude dans les questionnaires à choix multiple. Les méthodes étudiées avaient pour objectif de mettre en évidence des patrons de réponses aberrants au regard du résultat obtenu par le candidat et des difficultés individuelles des items composant le questionnaire (notamment lorsque des candidats répondent correctement à diverses questions difficiles alors qu’ils échouent à des questions plus faciles.).
La triche par copie sur un autre candidat constitue un cas particulier où des informations complémentaires peuvent être prises en considération pour évaluer les risques. Elle implique en effet la présence de deux acteurs : un candidat, dit copieur, recopie certaines réponses d’un autre candidat, dit fournisseur, qui peut ou non être délibérément consentant.
L’enjeu est de déterminer si un couple de candidats ayant pris part au test a occasionné une triche. La similitude des réponses apportées par les paires de candidats est quantifiée par un indice de test.
Si cet indice est trop éloigné des indices standards, alors on considère que les réponses des deux candidats constituent un cas de triche. L’idée générale est que deux candidats qui répondent correctement à une même série de questions, et incorrectement à une autre, seront fortement suspectés de triche.
Une comparaison de cinq modèles testés sur des données simulées a été réalisée. Des séries de réponses ont été générées et une triche a été simulée en forçant certaines réponses d’un candidat (copieur) à être identiques à celles du fournisseur. À chaque modèle correspond une probabilité de répondre correctement différente, à compétence et paramètres de questions fixés.
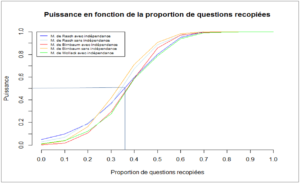
La figure ci-dessous nous renseigne sur la puissance des modèles utilisés en fonction de la proportion du nombre de questions copiées. Les analyses présentées sont effectuées avec un risque théorique de 1%[1], sur un examen fictif de 50 items. Lorsque la proportion de questions recopiées augmente, le taux de détection augmente logiquement.
Pour une proportion de questions recopiées située entre 30 et 40%, les modèles ont une puissance de détection d’environ 50%. Si la moitié des questions est copiée, les cas litigieux sont détectés environ 8 fois sur 10 quel que soit le modèle utilisé. Ce taux de détection approche les 100% lorsque 70% des questions sont copiées et à partir de 25%, la méthode « Birnbaum » sans indépendance apparait comme la plus puissante.
Toutefois, dans le contexte du TEFnous privilégions le modèle de Rash sans indépendance, dont les performances sont très proches.
Puissance des statistiques de test en fonction de la proportion de questions copiées
Les analyses statistiques menées sur les différents indices de détection de comportements suspicieux nous permettent d’identifier des moyens automatisables de prévenir et détecter la fraude dans les épreuves à choix multiple du TEF.
Une revue régulière des méthodes existantes et une analyse plus précise des comportements suspicieux permettent d’améliorer en continu la puissance de détection des cas suspects et contribuent au maintien de l’intégrité des résultats.
[1] Il y a ainsi 1% de chance d’accuser à tort deux candidats d’avoir triché ensemble.






